分布式计算框架——MapReduce
MapReduce的核心思想是”分而治之“。
MapReduce介绍
MapReduce设计构思
MaReduce是一个分布式运算程序的编程框架,简化了并行计算,降低并行应用的入门门槛。其设计思想体现如下:
- 分而治之
对互相之间不具备计算依赖关系的大数据才去分而治之的策略
- Map和Reduce
用Map和Reduce提供了高阶的并行编程抽象模型
Map:对一组数据进行某种重复式的处理
Reduce: 对Map的中间结果进行进一步的整理
MapReduce 定义了两个抽象的编程接口,让用户实现:
map: (k1; v1) ->[(k2; v2)]
Reduce: (k2; [v2]) -> [(k3; v3)]
- MR框架
- MR AppMaster: 负责整个程序的过程调度和状态协调
- MapTask: 负责map阶段的数据处理
- ReduceTask: 负责Reduce阶段的数据处理
MR编程规范
MR的开发一共8个步骤,Map:2 Shuffle:4 Reduce:2
Map阶段
- 设置InputFormat类,将数据切分为(k1,v1)
- 自定义Map逻辑,将上述的输入转换为(k2,v2)
Shuffle阶段
- 对k2v2进行分区
- 对不同分区的数据按照相同的key进行排序
- 对分组过的数据进行初步规约,降低数据的网络拷贝
- 对数据进行分组,相同的key和val放入同一个集合中
Reduce阶段
- 对多个Map任务的结果进行排序以及合并,编写Reduce实现自己的逻辑,转为新的k3v3
- 设置OutputFormat处理并保存Reduce输出的kv数据
Mapper、Reducer抽象类介绍
上述的八个步骤都是一个class类。MR中,最重要的就是mapper和Reducer类
- Mapper抽象类
四个重要方法
- setup 初始化方法
- map:读取的每一行数据,会调用一次map
- cleanup:maptask执行完之后,会调用cleanup。可以做一些连接断开,资源关闭的操作
- run:更精细的控制MapTask的执行
- Reducer抽象类
- setup
- reduce
- cleanup
- run
WordCount示例
数据准备
cd /export/servers vim wordcount.txt #添加以下内容: hello hello world world hadoop hadoop hello world hello flume hadoop hive hive kafka flume storm hive oozie hdfs dfs -mkdir /wordcount/ hdfs dfs -put wordcount.txt /wordcount/定义mapper类
/** keyin : long -> LongWritable valin: String -> Text keyout: String -> Text valout: Long -> LongWritable **/ public class MapTask extends Mapper<LongWritable, Text, Text, LongWritable>{ /* context:上下文对象 */ protected void map(LongWritable key, Text value, Context context){ //1. 获取v1的数据,文本中的一行 String val = value.toString(); //2. 切割单词 String[] words = val.split(" "); Text text = new Text(); LongWritable longWritable = new LongWritable(1); // 3. 遍历单词,发给reduce for (String word : words){ text.set(word); context.write(text, longWritable); } } }定义Reducer类
public class ReduceTask extends Reducer<Text, LongWritable, Text, LongWritable>{ protected void reduce(Text key, Interable<LongWritable> values, Context context){ long v3 = 0; for (LongWritable longWritable : value){ v3 += longWritable.get(); } context.write(key, new LongWritable(v3)); } }定义主类,提交任务
略
MR的运行机制(重要)
MapTask工作机制
数据读取组件InputFormat(默认为TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到split,有多少个split就启动多少个MapTask
关于split与block
将输入文件切分为split之后,由RecordReader对象(默认为LineRecordReader)进行读取,以**\n作为分隔符,返回<key,value>,key表示每行首字符的偏移值**,Value表示这一行文本内容
<key,value>进入用户自定义的Mapper类,执行map函数。每读取一行,调用一次
以下是Map的shuffle过程
Mapper逻辑结束后,将Mapper的每条结果通过context.write进行collect数据收集。在collector中,会先进行分区处理。
Partitioner,根据Key或Value以及Reducer的数量决定当前的数据输出交给哪个Reduce Task处理。 默认HashPartitioner对Key Hash后再以Reducer的数量取模。
对于数据不平衡的情况,可能就要自定义分区算法
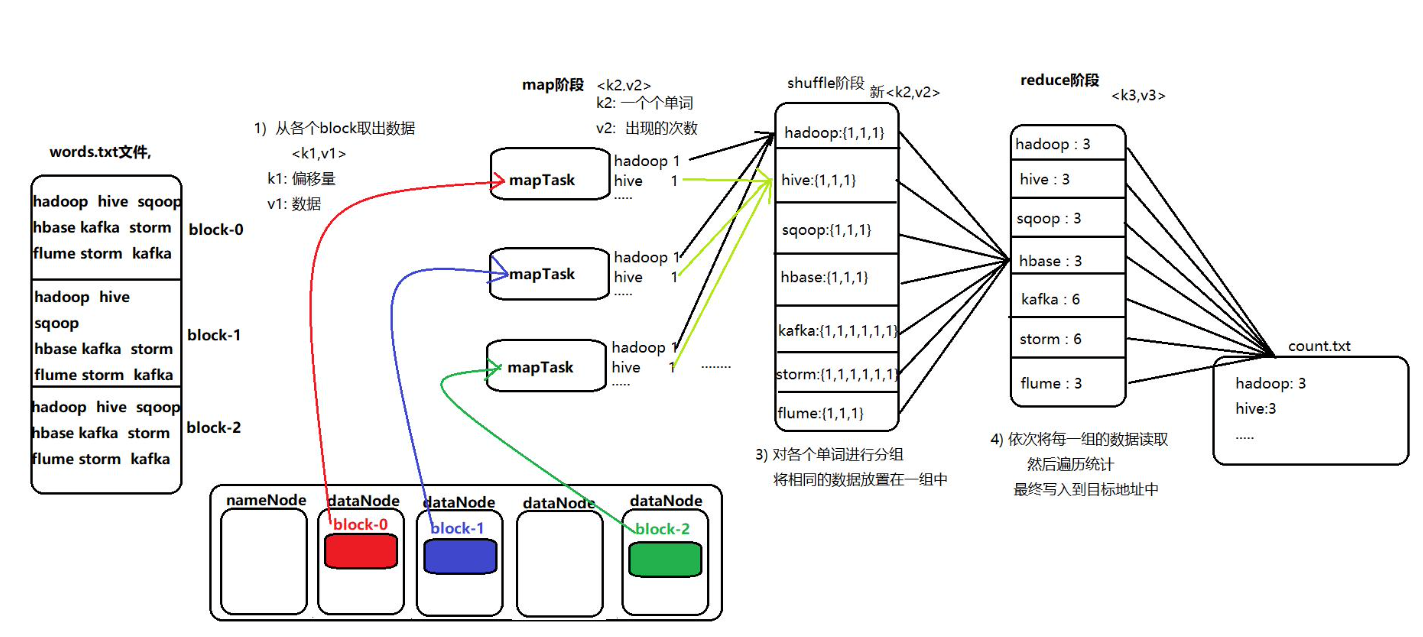
数据写入内存(环形缓冲区),作用是收集mapper结果,减少磁盘IO的影响。
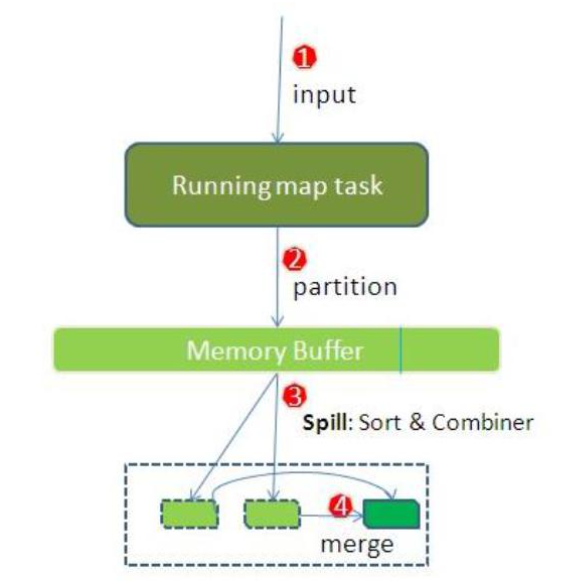
环形缓冲器是一个数组,存放kv的序列化数据、元数据信息(分区、kv的起始位置、value的长度)
缓冲区默认的大小是100M。 当缓冲区的数据达到阈值(默认0.8*100=80MB),会spill溢写数据到磁盘。溢写程序是一个单独的线程,锁定80M内存,输出结果往剩下的20M内存中写。
这里写图片描述 存在缓冲区的数据包括存放kv数据的kvbuffer和存放索引的kvmeta。
索引包括:value的起始位置、key的起始位置、partition的值、value的长度
排序(sort),对80MB空间内的Key做排序。如果设置为Combiner,在之后会将具有相同key的kv的v合并在一起。
程序先把Kvbuffer中的数据按照partition值和key两个关键字升序排序(快速排序),移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
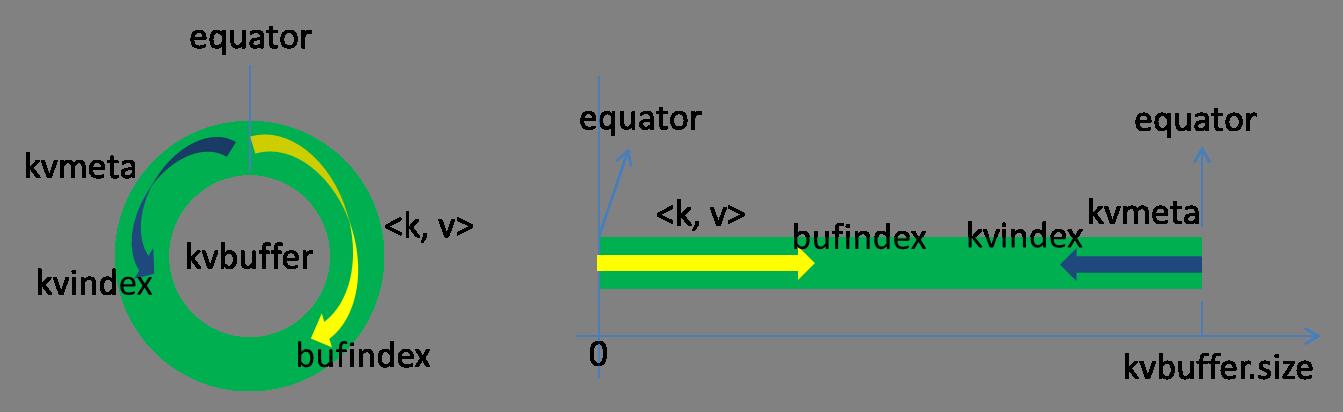
溢写文件(spill)。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到溢写文件.out中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。

这里写图片描述 归并(merge)。针对同一个Mapper的多个spill文件的merge。如果文件比较大,会进行多次spill,产生多个spill文件,需要对多个溢写文件进行归并(merge)并排序,如果有Combine则进行,最后保存为一个文件写入磁盘,并为这个文件提供一个索引,记录每个partition对应的数据偏移量。
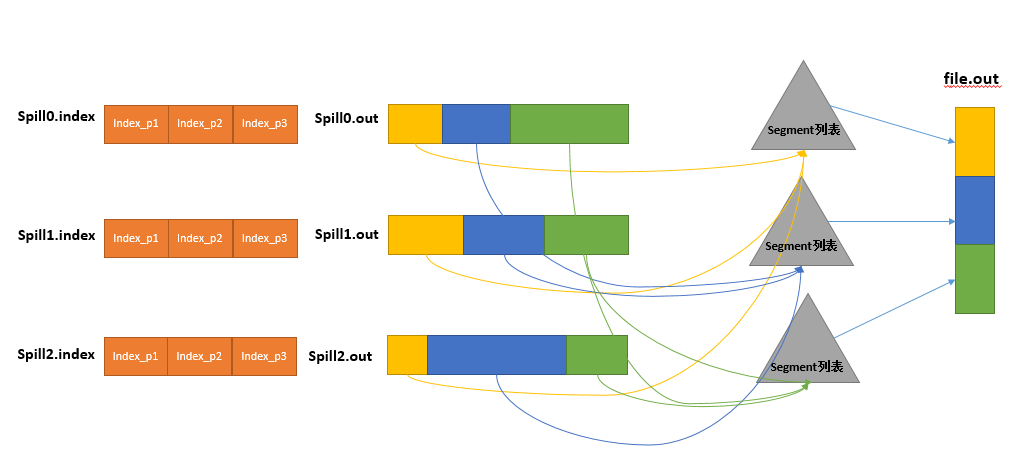
这里写图片描述 使用堆排序,
归并:<a,1>,<a,2> => <a,[1,2]> ?纠正:map端应该是没有这个操作的
ReduceTask工作机制
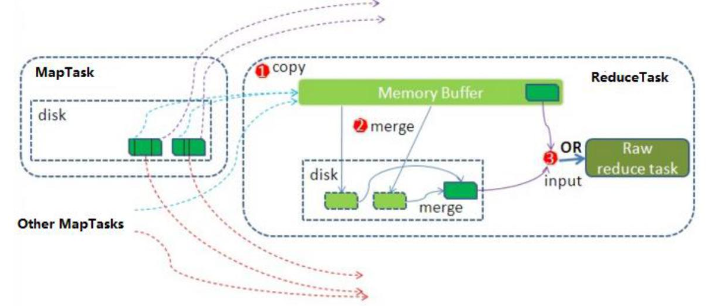
- Copy阶段。Reduce进行启动Fetcher线程去copy数据,通过http方式请求MapTask获取属于自己的文件
- Merge阶段。针对不同Mapper的partition数据进行的merge。从不同map端copy过来的数据会存放在内存缓存区中。达到溢写条件时,会在磁盘中生成溢写文件(inMemoryMerger),然后启动磁盘到磁盘的Merge方式生成最终的文件(onDiskMerger)。
- 归并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据进行排序
- 对排序后的kv调用Reduce方法。键相等的键值对调用一次reduce方法,产生零个或多个键值对,把输出kv写到hdfs文件中。
Shuffle过程
map阶段处理的数据传递给reduce阶段的流程称为shuffle。
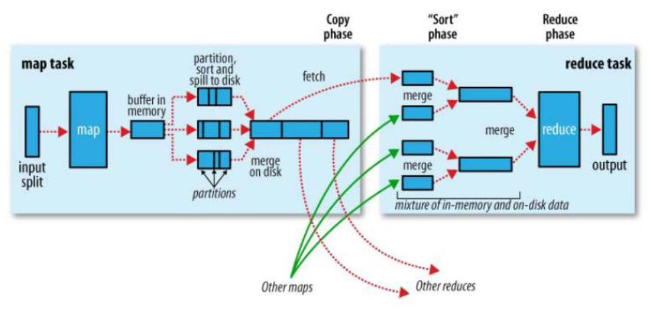
- collect阶段。将MapTask的结果输出到默认为100M的环形缓冲区,保存的是kv、partition分区等信息
- spill阶段。达到阈值时,溢写到本地磁盘,在写之前有一次排序的操作,如果配置里combiner,还会将有相同分区号和key的数据进行排序
- merge阶段。把所有溢写的临时文件进行一次合并操作,确保一个MapTask产生一个中间数据文件
- copy阶段。reduceTask启动fetcher线程到以及完成MapTask的节点上复制自己的数据,默认保存在缓冲区中,达到阈值后,写到磁盘上
- merge阶段。在ReduceTask复制数据的同时,后台会开启两个线程对内存到本地的数据文件进行合并操作
- sort阶段。在合并的同时,会进行排序操作,MapTask以及进行了局部的排序,ReduceTask只需要保证copy的数据的最终整体有效性即可。
例:社交粉丝数据分析
需求
以下是 qq 的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数 据中的好友关系是单向的) A:B,C,D,F,E,O
B:A,C,E,K
C:A,B,D,E,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
思路
- 第一步
Map
读一行 A:B,C,D,F,E,O
输出:<A,B>、<A,C>、<A,D>、<A,F>、<A,E>、<A,O>
Reduce
拿到数据<C,A><C,B><C,E><C,F><C,G>... 相同的key会分到了一个MapTask
输出:<A-B-E-,C>
..
- 第二步
Map
读<A-B-E-,C>
输出<A-B,C>、<A-E,C>
Reduce 读<A-B,C>、<A-B,E>
输出:<A-B ,CE>
参考