Kafka基础介绍
kafka 是最初由 linkedin 公司开发的,使用 scala 语言编写,kafka 是一个分布 式,分区的,多副本的,多订阅者的日志系统(分布式 MQ 系统),可以用于搜 索日志,监控日志,访问日志等。
消息队列
消息队列的介绍
消息是指在应用之间传递的数据,消息可以是文本字符串、嵌入对象...
消息队列是一种应用间的通信方式,消息发布者把消息发布到MQ中,消息使用者从MQ中取消息。双方都不知道对方的存在。
消息队列的应用场景
异步处理
- 多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间
不使用消息队列
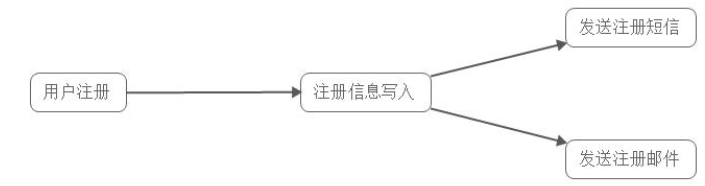
假设每个子系统的处理时间是50ms,系统需要在发送结束后返回,需要耗时100ms
使用消息队列
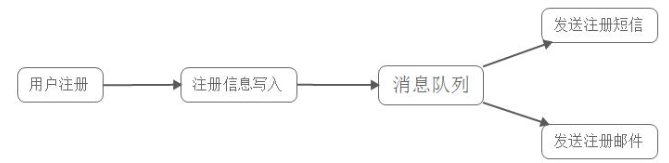
后端在写入消息队列后就返回给客户端
应用解耦
- 多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败

客户端上传图片后,图片上传系统将图片信息写入消息队列,直接返回成功。
人脸识别系统从消息队列中取数据。
限流削峰
- 广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况

请求先加入消息队列,做一次缓冲,减小业务处理系统压力
队列设置长度,对于秒杀商品,后入队列的请求被抛弃
消息驱动的系统
- 系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理

消息队列的两种模式
点对点模式
- 消息队列
- 生产者
- 消费者

特点
- 每个消息只有一个接受者
- 生产者和消费者之间没有依赖性
- 消费者消费后要向队列应答成功,以便消息队列删除消息
发布/订阅模式
- 角色主题
- 发布者
- 订阅者
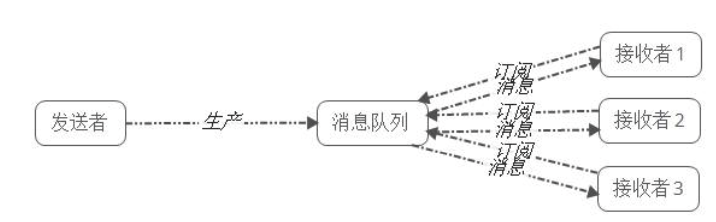
特点
- 每个消息可以有多个订阅者
- 发布者和订阅者有时间上的依赖性,针对某个主题,必须创建订阅者才能消费发布者的消息
- 订阅者需要提前订阅该角色主题
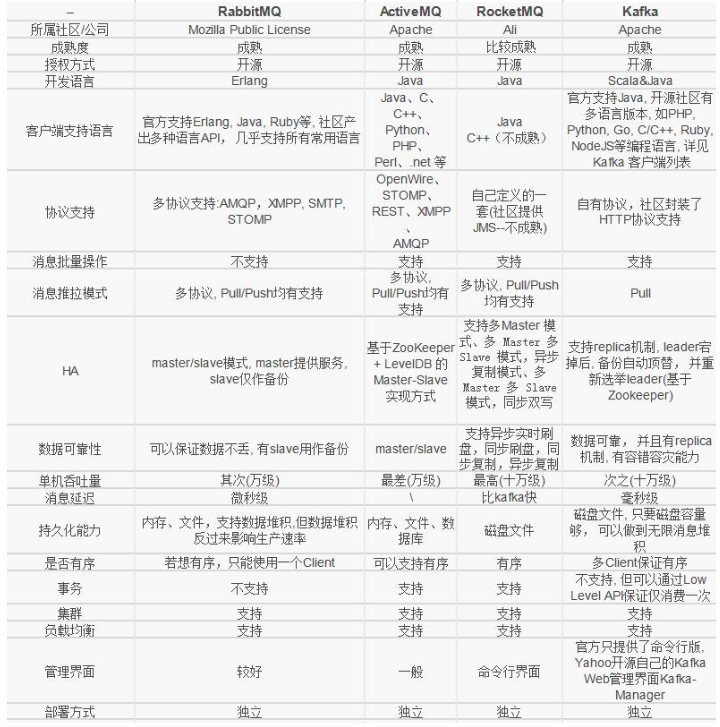
常用的消息队列
- RabbitMQ
主流的消息中间件之一
- ActiveMQ
- RocketMQ
出自阿里
- Kafka
- Pulsar
Kafka基础
基本介绍
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
优势
- 可靠性
- 可扩展性
- 耐用性
- 性能
应用场景
指标分析
聚合来自分布式应用程序的统计信息
日志聚合
从多个服务器收集日志,并使他们以标准的格式提供给多个服务器
流式处理
对接流式处理框架(spark,storm,flink)
- 传递消息
- 活动跟踪
Kafka架构及组件
Kafka架构
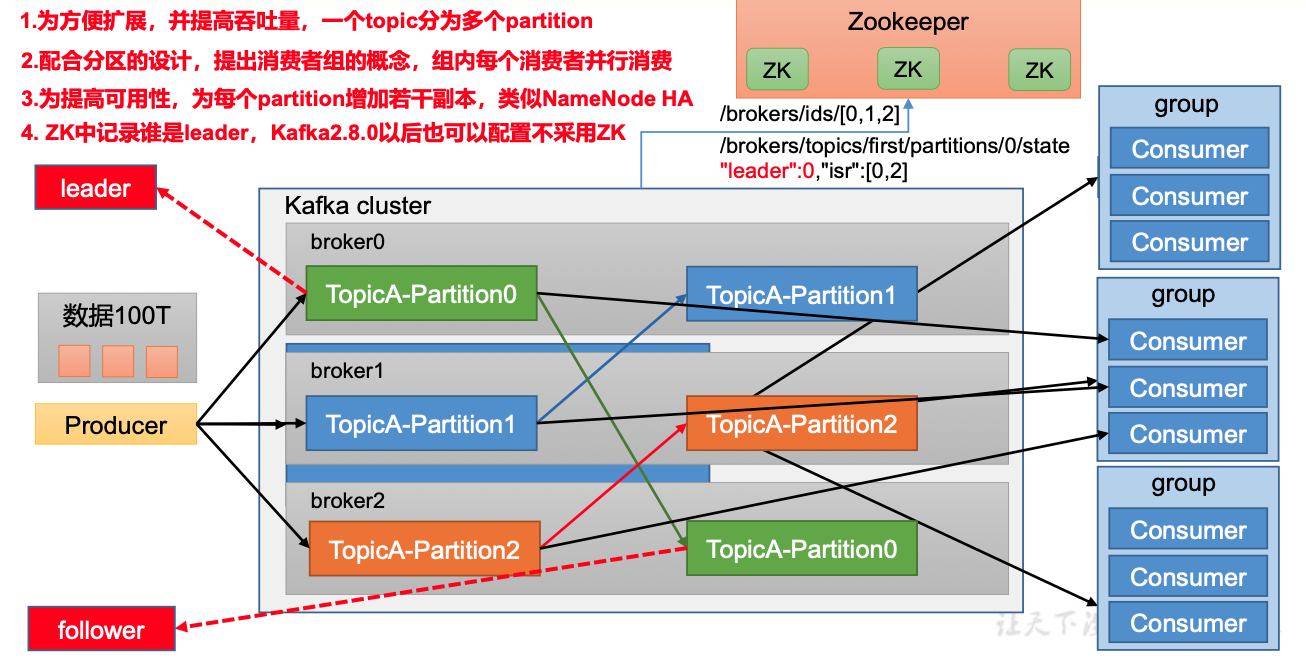
- topic:每条发布到Kafka的消息的类别
- partition:物理上的概念,每个topic包含一个或者多个partition
- segment:一个partition存在多个segment文件段,每个segment包含.log和.index
- producer:生产者
- consumer:消费者
- consumer group:消费者组
- .log:存放数据文件
- .index:存放.log文件的索引数据
Kafka主要组件
producer生产者
生成消息,通过topic进行归类
topic主题
- Kafka将消息以topic为单位进行归类
partition 分区
一个topic可以有多个分区,每个分区保存部分topic的数据。
一个broker服务下,可以创建多个分区
每一个分区有一个编号,从0开始
每一个分区内的数据是有序的,但不能保证全局有序,有序指消费时的顺序是否是生产时的顺序
consumer 消费者
消费数据
consumer group 消费者组
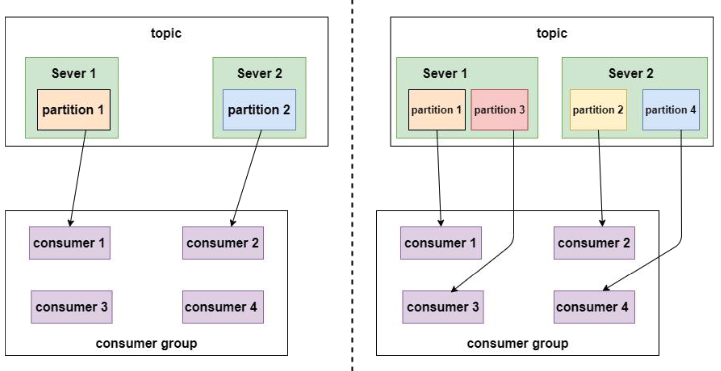
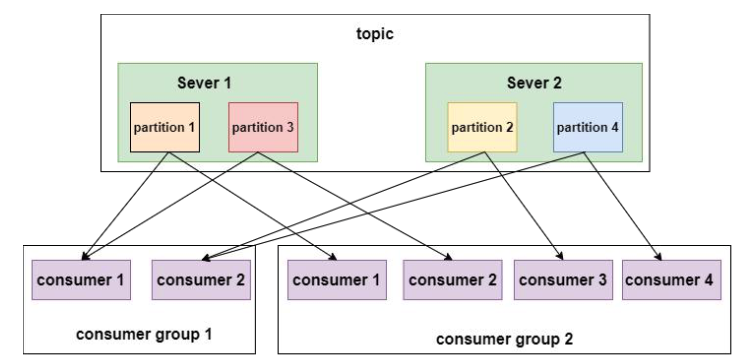
消费者组由一个或多个消费者组成,同一个组中的消费者对同一个消息只消费一次
如果不指定,则所有的消费者属于一个默认的组
每个分区只能由同一个消费者组的一个消费者来消费,可以由不同的消费者组来消费。
某一主题上的分区数,对于消费该主题的同一个消费者组下的消费者,消费者数量要小于等于分区的数量。
分区副本
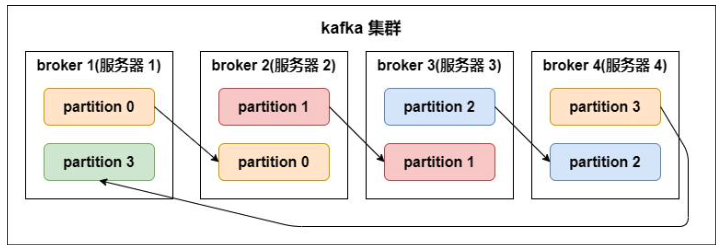
副本因子要小于等于可用的broker数量
副本因子操作是以分区为单位的,每个分区都有各自的主副本和从副本
主副本-leader,从副本-follower。 处于同步状态的副本称为in-sync-replicas(ISR)