Kafka Broker
本章主要介绍Kafka Broker
Broker 工作流程
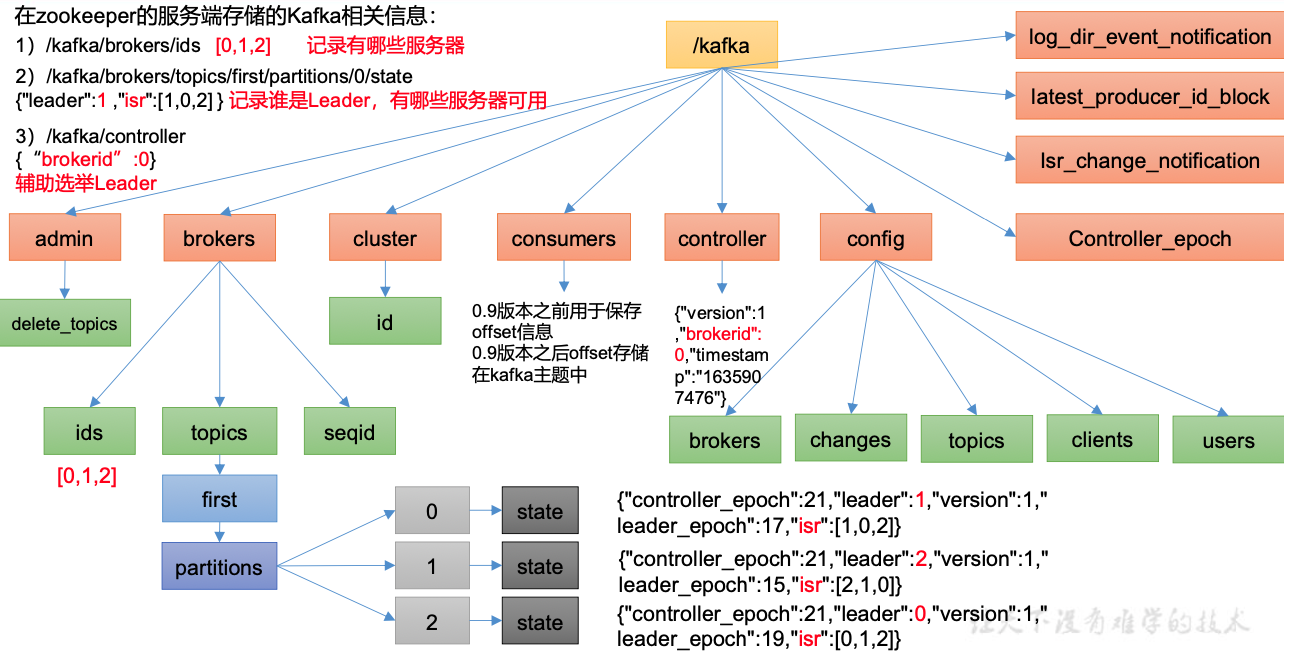
Zookeeper存储的Kafka信息
Kafka Broker总体工作流程
节点服役和节点退役
服役新节点
新节点准备
执行负载均衡操作
a. 创建一个要均衡的主题
{
"topics": [
{"topic": "first"}
],
"version": 1
}
b. 生成一个负载均衡计划
bin/kafka-reassign-partitions.sh -- bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
c. 创建副本存储计划 increase-replication-factor.json
d. 执行副本存储计划
bin/kafka-reassign-partitions.sh -- bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
退役旧节点
- 创建要均衡的主题
{
"topics": [
{"topic": "first"}
],
"version": 1
}
- 创建执行计划
bin/kafka-reassign-partitions.sh -- bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
- 根据执行计划创建副本存储计划
- 执行副本存储计划
Kafka副本
副本基本信息
副本作用:提高数据可靠性
默认1个副本,生产环境一般配置2个
副本分为:Leader和Follower。 生产者只会把数据发给Leader,Follower找Leader同步数据
所有副本统称为AR(Assigned Replicas)
AR = ISR + OSR
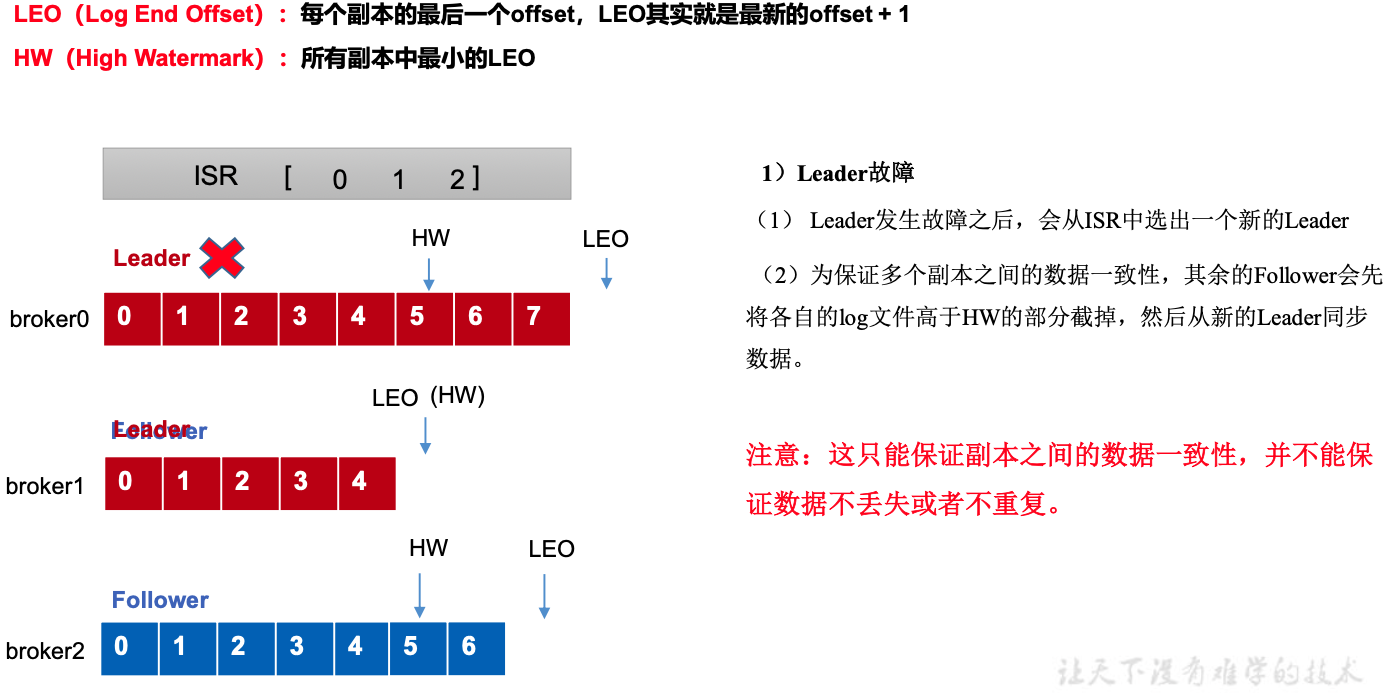
ISR:表示和Leader保持同步的Follower集合。长时间未通信的Follower会被踢出ISR。Leader发生故障后,就会ISR中选举新的Leader
OSR: 表示Follower与Leader副本同步时,延迟过多的副本
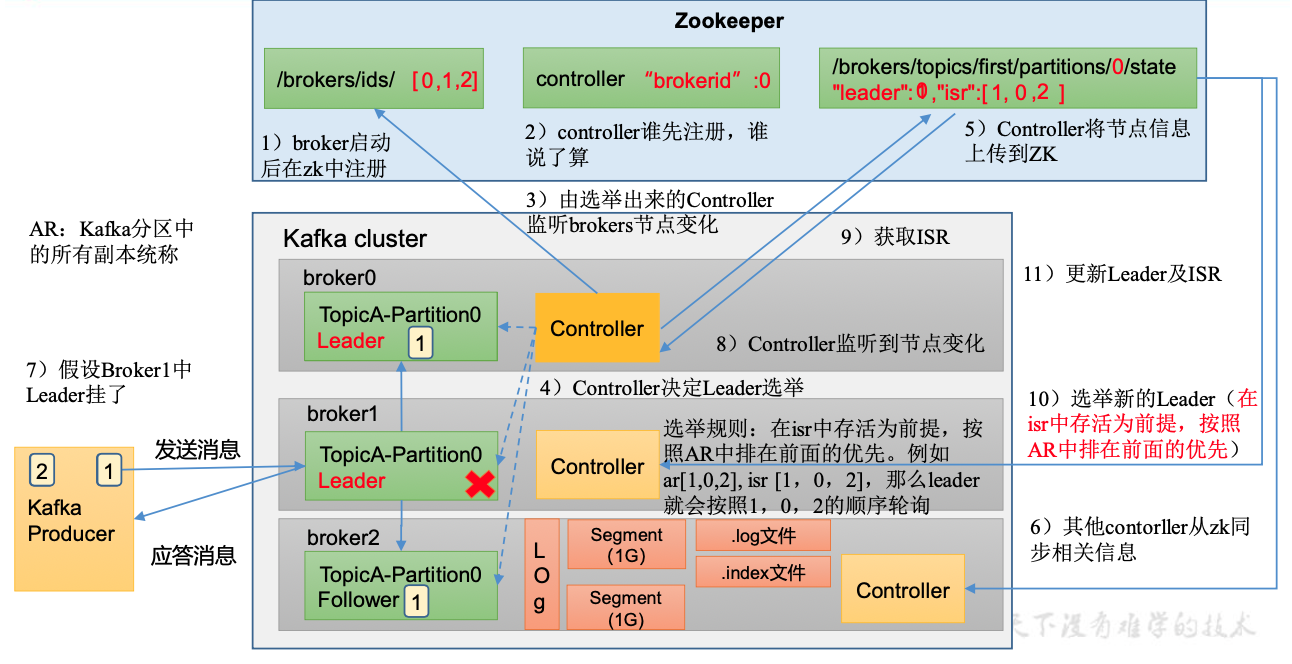
Leader选举流程
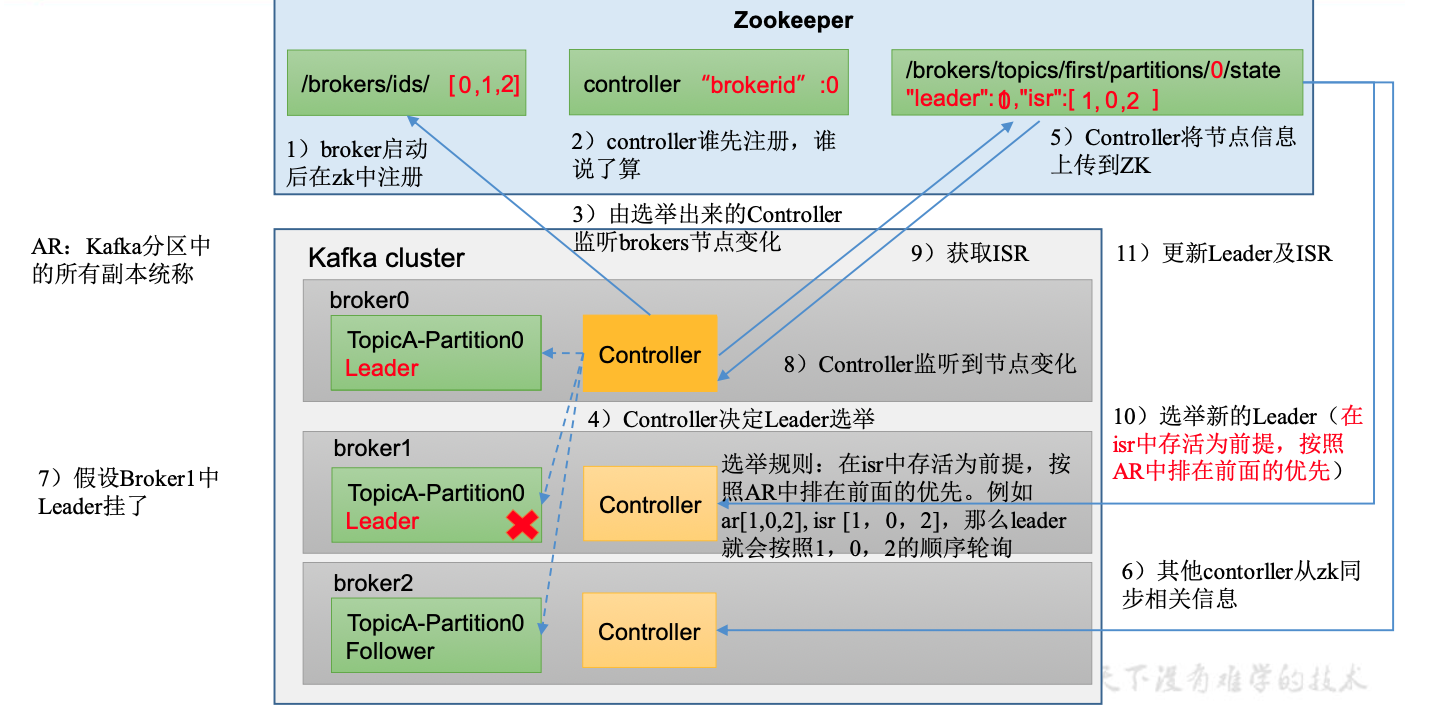
Leader 和 Follower 故障处理细节
Follower故障处理

Leader故障处理
分区副本分配
手动调整分区副本存储
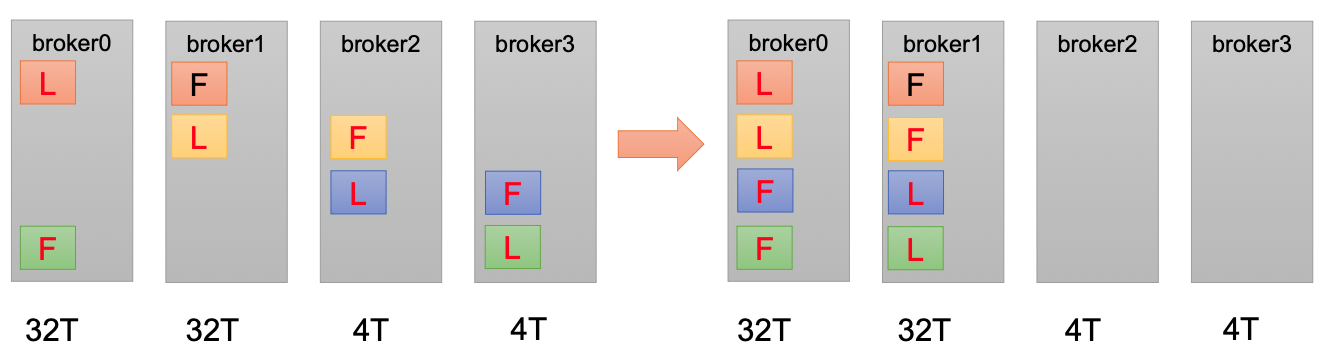
- 创建副本存储计划
{
"version":1,
"partitions":[{"topic":"three","partition":0,"replicas":[0,1]}, {"topic":"three","partition":1,"replicas":[0,1]}, {"topic":"three","partition":2,"replicas":[1,0]}, {"topic":"three","partition":3,"replicas":[1,0]}]
}
- 执行副本计划
bin/kafka-reassign-partitions.sh -- bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
Leader Partition 负载平衡
- auto.leader.rebalance.enable,默认是true
- leader.imbalance.per.broker.percentage, 默认是10%
- leader.imbalance.check.interval.seconds, 默认值300秒。检查leader负载是否平衡的间隔时间
比例计算:

对broker3,partition1Leader应该是它,但不是,不平衡数+1,AR副本数4,不平衡率=1/4
建议设置为关闭
增加副本因子
- 创建副本存储计划
{"version":1,"partitions":[{"topic":"four","partition":0,"replicas":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"topic":"four","partition":2,"replicas":[0,1,2]}]}
- 执行副本存储计划
bin/kafka-reassign-partitions.sh -- bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
文件存储
文件存储机制
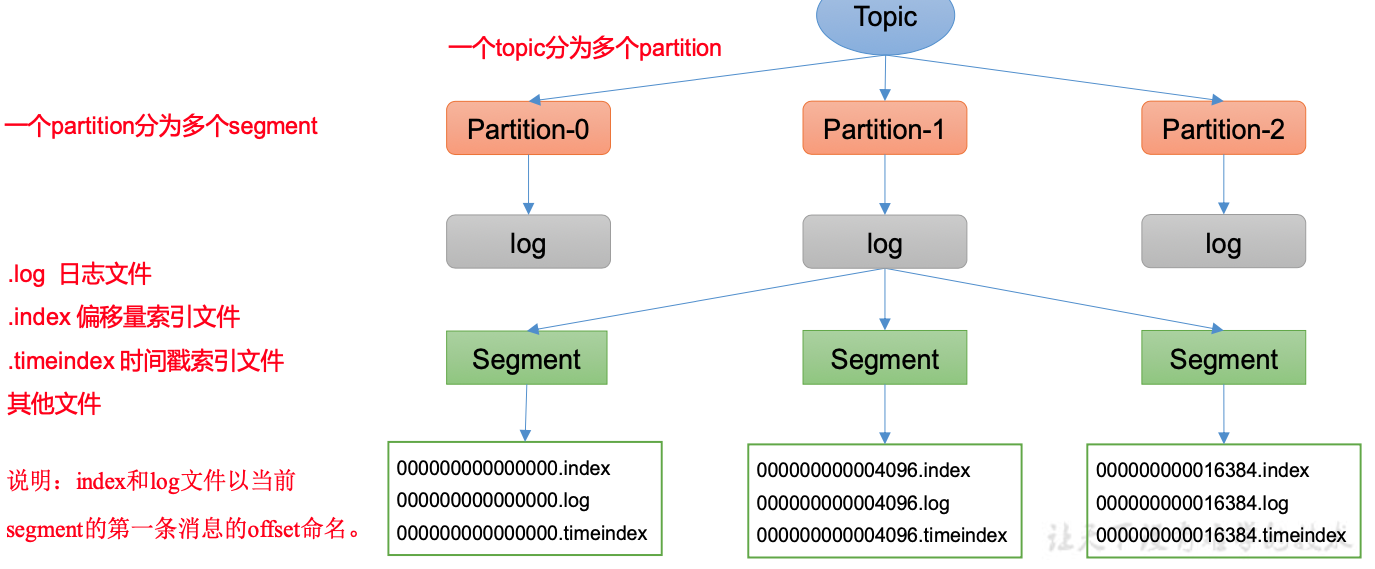
- 每个partition对应一个log文件
- producer生产的数据会被追加到log文件末端
- Kafka采用了分片和索引机制
- 每个partition分为多个segment,包含index文件,log文件,timeindex文件
index文件和log文件详解
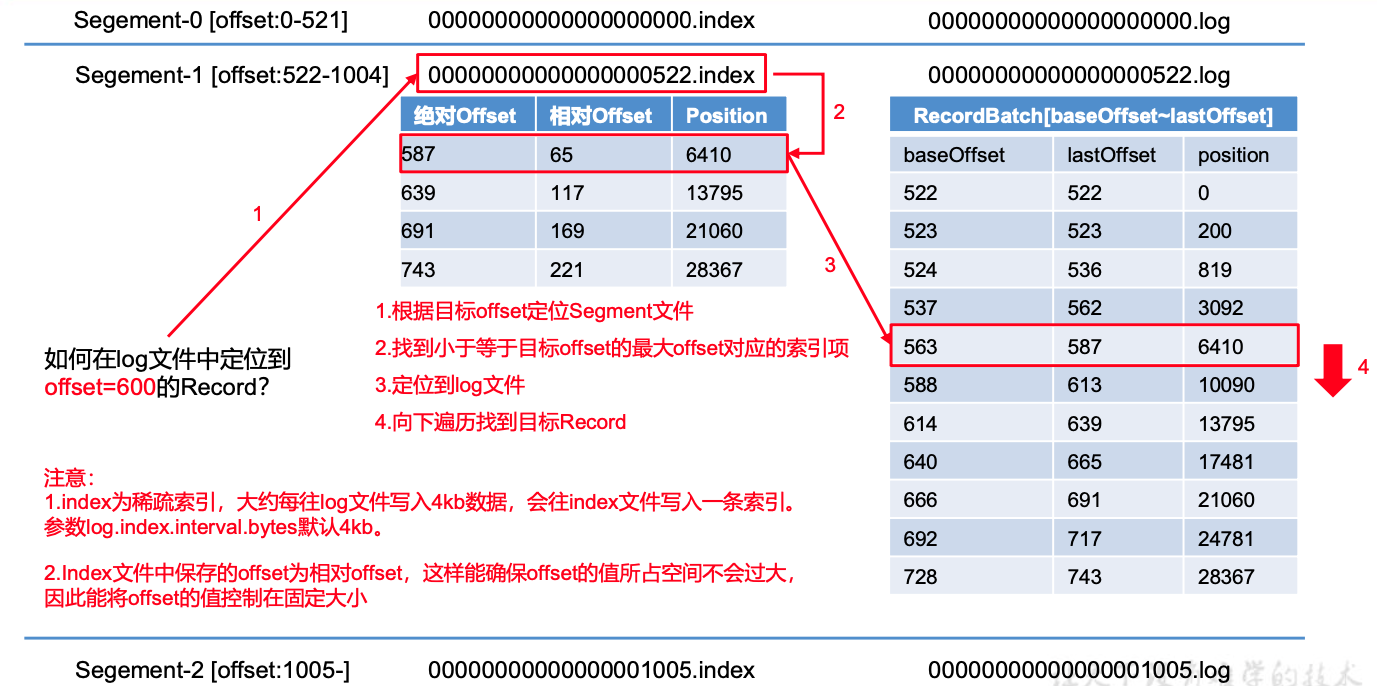
index:65,6410 表示数据文件中的第65个message,它的偏移地址是6410
- 稀疏索引
文件清理策略
- 默认保存7天,修改参数有
- log.retention.hours(minutes,ms)
- log.retention.check.interval.ms
delete 日志删除,将过期数据删除
log.cleanup.policy = delete
- 基于时间:默认。以segment中所有记录中的最大时间戳作为该文件的时间戳
- 基于大小:默认关闭,超过设置的日志总大小,删除最早的segment
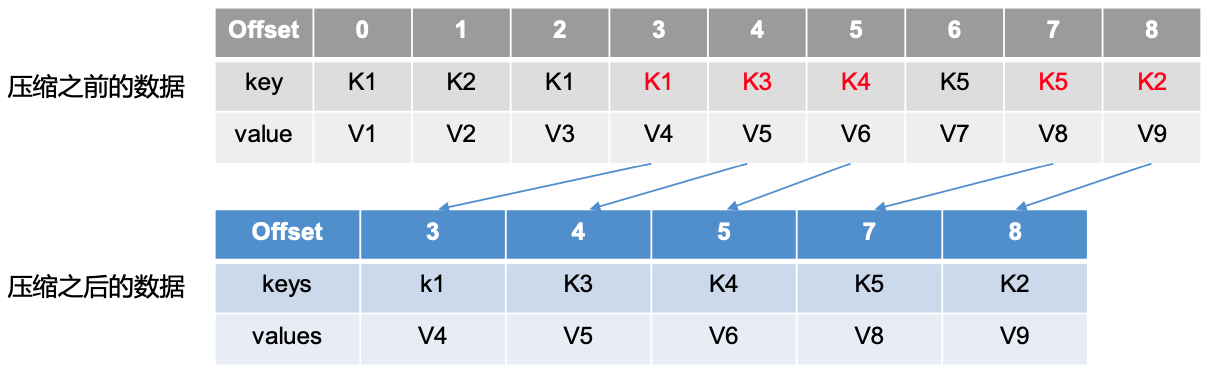
compact日志压缩
对于key相同的不同value,只保留最后一个版本
高效读写数据
- Kafka是分布式集群,并行度高
- 读数据采用稀疏索引,可以快速定位
- 顺序写磁盘
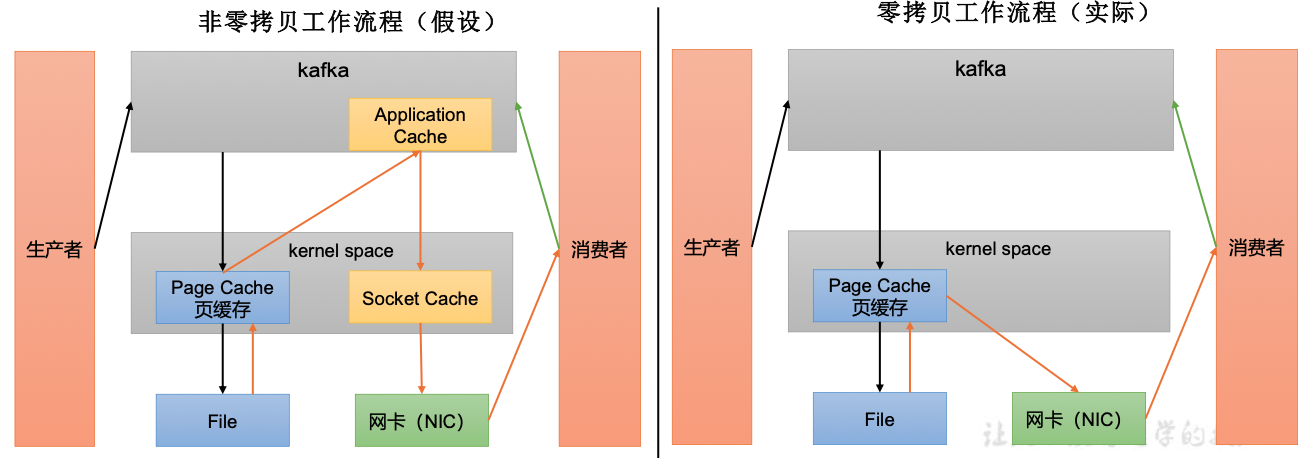
- 页缓存+零拷贝技术
零拷贝: Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高
PageCache: 页缓存:Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存 都当做了磁盘缓存来使用